Introducing Levels of Reproduction and Replication in Machine Learning
Using Reproducibility in Machine Learning Education

Hello again,
I am Mohamed Saeed and this is my second blog post for the 2023 Summer of Reproducibility Fellowship. As you may recall from my previous post, I am working on the Using Reproducibility in Machine Learning Education project with Fraida Fund as my mentor. My goal is to create interactive open educational resources that teach reproducibility and reproducible research in machine learning (ML) as I proposed.
In this post, I will share with you some of the progress I have made so far, as well as some of the challenges I have faced and how I overcame them. I will also highlight some of the specific accomplishments that I am proud of and what I plan to do next.
Reproducing “On Warm Starting Neural Network Training”
This material is a reproduction of the paper “On Warm Starting Neural Network Training” by Jordan T. Ash and Ryan P. Adams (2020). This paper investigates the effect of warm-starting neural networks, which means using the weights of previous models trained on a subset of the data, to train on a new dataset that has more data.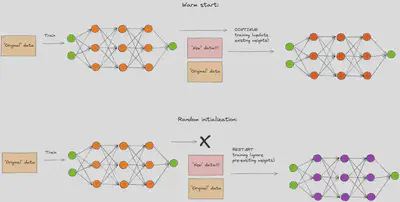
The paper also shows that this method can lead to lower test accuracy than starting from scratch with random weights, even though the training loss is similar. The paper also proposes a simple way to improve the test accuracy of warm-starting by adding some noise to the previous weights.
To reproduce this paper, I followed a systematic approach that ensured reliable results. This approach involved:
- Reading the paper and its main claims carefully.
- Finding out what resources the authors shared, such as code, data, and models.
- Looking for additional materials online that could help me save time and fill in the gaps left by the authors.
- Setting up the environment and dependencies needed to run the code smoothly.
- Writing code and updating any outdated functions that might cause errors.
- Running the code and verifying that it matched the results reported in the paper.
- Analyzing and interpreting the results and comparing them with the paper’s findings.
I used Chameleon as my platform for running and documenting my reproduction experiments. Chameleon is a large-scale, reconfigurable experimental platform that supports computer science systems research. It allows users to create and share Jupyter notebooks that can run Python code on Chameleon’s cloud servers.
I created a GitHub repository where you can find all related to my reproduction work in the form of interactive jupyter notebooks that will help you learn more about machine learning and reproducibility of machine learning research.
Challenges
Reproducing a paper is not an easy task. I faced several challenges along the way. One of the biggest challenges was the lack of code and pretrained models from the authors. This is a common problem for many reproducibility projects. Fortunately, I found a previous reproducibility publication for this paper on ReScience journal. I used some of their code and added some new functions and modifications to match the original paper’s descriptions. I also encountered other challenges that I discussed in the notebooks with the solutions that I applied.
How to use this material?
This material is a series of notebooks that walk you through the paper and its claims, experiments, and results. You will learn how to analyze, explain, and validate the authors’ claims. To get started, I suggest you skim the original paper briefly to get the main idea and the public information. This will help you understand how the authors could have been more clear and transparent in some sections. I have given clear instructions and explanations in the notebooks, as well as how I dealt with the missing components. You can use this material for self-learning or as an assignment by hiding the final explanation notebook.
Conclusion and Future Work
In this blog post, I have shared with you some of my work on reproducing warm starting neural network training. I have learned a lot from this experience and gained a deeper understanding of reproducibility and reproducible research principles in ML.
I am very happy with what I have achieved so far, but I still have more work to do. I am working on reproducing the Vision Transformer: An Image is Worth 16x16 Words paper by Alexey Dosovitskiy et al. This time my approach is to use the available pretrained models provided by the authors to verify the claims made in the paper. However, there are some challenges that I face in reproducing the paper. For example, some of the datasets and code that the authors used are not publicly available, which makes it hard to replicate their experiments exactly. These challenges are common in reproducing research papers, especially in computer vision. Therefore, it is important to learn how to deal with them and find ways to validate some of the claims.
I hope you enjoyed reading this blog post and found it informative and interesting. If you have any questions or feedback, please feel free to contact me. Thank you for your attention and stay tuned for more updates!
Mohamed Saeed
Computer and Communications Engineering student
Computer and Communication Engineering student interested in NLP and machine learning research